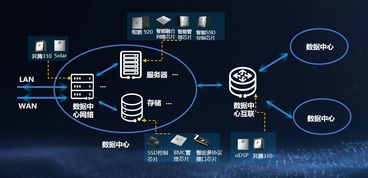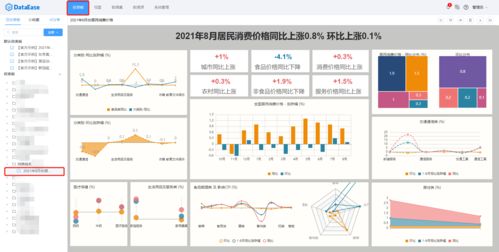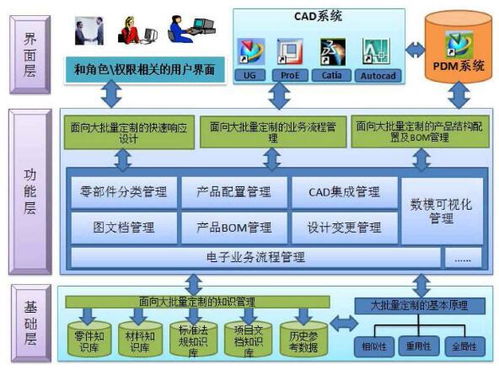
在現(xiàn)代信息技術中,產(chǎn)品架構與數(shù)據(jù)處理密不可分,它們共同構建了系統(tǒng)的核心能力。一個優(yōu)秀的產(chǎn)品架構不僅關注功能模塊的組織,更強調(diào)數(shù)據(jù)處理流程的設計,以確保系統(tǒng)能夠高效、可靠地處理海量信息。本文將探討產(chǎn)品架構中數(shù)據(jù)處理的關鍵要素、常見模式及優(yōu)化策略。
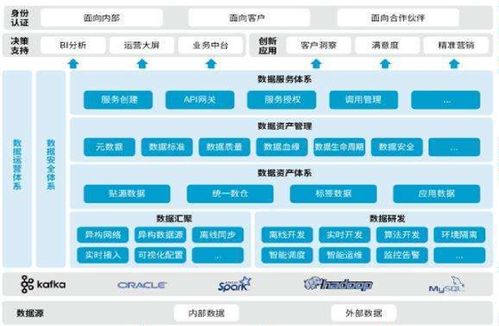
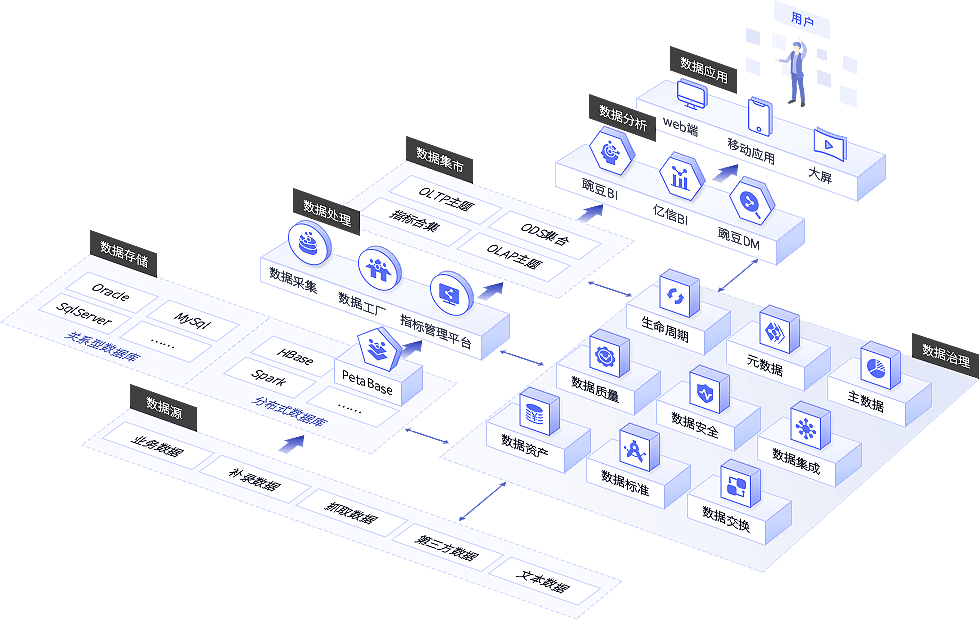
產(chǎn)品架構的數(shù)據(jù)處理部分通常包括數(shù)據(jù)采集、存儲、計算和分析等環(huán)節(jié)。數(shù)據(jù)采集負責從用戶端或外部系統(tǒng)收集原始數(shù)據(jù),例如通過API接口、日志文件或傳感器輸入;數(shù)據(jù)存儲則涉及選擇適當?shù)臄?shù)據(jù)庫或文件系統(tǒng),如關系型數(shù)據(jù)庫、NoSQL或分布式存儲,以支持數(shù)據(jù)的持久化和快速檢索;數(shù)據(jù)計算環(huán)節(jié)利用批處理或流處理技術,如Spark或Flink,對數(shù)據(jù)進行清洗、轉(zhuǎn)換和聚合;數(shù)據(jù)分析通過可視化工具或機器學習模型,提取業(yè)務洞察。這些環(huán)節(jié)必須緊密集成,避免瓶頸,確保整體架構的流暢性。
常見的數(shù)據(jù)處理架構模式包括Lambda架構和Kappa架構。Lambda架構結(jié)合批處理和流處理,適用于需要高精度和實時性的場景,例如金融交易系統(tǒng);Kappa架構則簡化處理流程,專注于流處理,適用于快速迭代的互聯(lián)網(wǎng)應用。選擇合適模式時,需考慮數(shù)據(jù)量、時效性和系統(tǒng)復雜度。微服務架構的興起使得數(shù)據(jù)處理可以模塊化部署,每個服務獨立處理自身數(shù)據(jù),提高了系統(tǒng)的可擴展性和維護性。
優(yōu)化數(shù)據(jù)處理的關鍵策略包括性能調(diào)優(yōu)和數(shù)據(jù)治理。性能方面,可以通過數(shù)據(jù)分區(qū)、索引優(yōu)化和緩存機制來提升處理速度;數(shù)據(jù)治理則涉及數(shù)據(jù)質(zhì)量監(jiān)控、安全合規(guī)和生命周期管理,確保數(shù)據(jù)的可靠性和合規(guī)性。實踐中,團隊應采用監(jiān)控工具實時跟蹤數(shù)據(jù)處理指標,并根據(jù)反饋持續(xù)改進架構。
產(chǎn)品架構中的數(shù)據(jù)處理是一個系統(tǒng)工程,需要平衡技術選型、業(yè)務需求與資源約束。通過合理設計架構并采用先進的數(shù)據(jù)處理技術,企業(yè)能夠構建出響應迅速、智能高效的產(chǎn)品,從而在競爭激烈的市場中脫穎而出。未來,隨著人工智能和邊緣計算的發(fā)展,數(shù)據(jù)處理架構將更趨智能化與分布式,為產(chǎn)品創(chuàng)新提供更強動力。